SpaCy pour l'extraction d'entités
La première version de spaCy a été publiée en 2015 et elle est rapidement devenue un cadre standard pour l'extraction d'entités de niveau entreprise (également connue sous le nom de NER).
Si vous avez un morceau de texte non structuré (provenant du web par exemple) et que vous voulez en extraire des données structurées, comme des dates, des noms, des lieux, etc. spaCy est une très bonne solution.
SpaCy est intéressant car plusieurs modèles pré-entraînés sont disponibles dans une vingtaine de langues. (voir la suite ici). Cela signifie que vous ne devez pas nécessairement former votre propre modèle pour l'extraction d'entités. Cela signifie également que, si vous souhaitez former votre propre modèle, vous pouvez partir d'un modèle pré-formé au lieu de partir de zéro, ce qui peut vous faire gagner beaucoup de temps.
SpaCy est considéré comme un framework de "qualité production" car il est très rapide, fiable et accompagné d'une documentation complète.
Cependant, si les entités par défaut supportées par les modèles pré-entraînés de spaCy ne sont pas suffisantes, vous devrez travailler sur "l'annotation des données" (également connue sous le nom d'"étiquetage des données") afin d'entraîner votre propre modèle. Ce processus prend énormément de temps et de nombreux projets d'extraction d'entités d'entreprise échouent à cause de ce défi.
Disons que vous voulez extraire les titres de postes à partir d'un texte (d'un CV par exemple, ou d'une page web d'entreprise). Comme les modèles pré-entraînés de spaCy ne supportent pas une telle entité par défaut, vous devrez apprendre à spaCy à reconnaître les titres de postes. Vous devrez créer un ensemble de données d'entraînement qui contient plusieurs milliers d'exemples d'extractions de titres de postes (et peut-être même beaucoup plus !). Vous pouvez utiliser un logiciel d'annotation payant comme Prodigy (créé par l'équipe de spaCy), mais cela implique quand même beaucoup de travail humain. Il est en fait assez courant de voir des entreprises embaucher un groupe de contractants pendant plusieurs mois pour mener à bien un projet d'annotation de données. Un tel travail est tellement répétitif et ennuyeux que les jeux de données résultants contiennent souvent beaucoup d'erreurs...
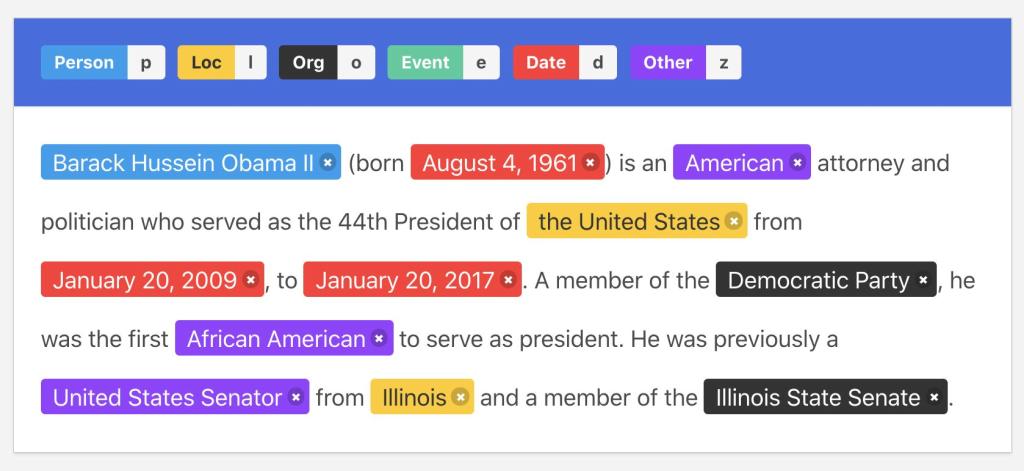 Exemple d'annotation de données
Exemple d'annotation de donnéesVoyons quelles solutions alternatives vous pourriez essayer en 2023 !


