John Doe is a Go developer at Google.
Qu'est-ce que l'étiquetage des parties du discours (POS) ?
L'objectif d'un marqueur de partie du discours est d'attribuer des parties du discours à chaque mot de votre texte. Un jeton est un mot, la plupart du temps, mais il peut également s'agir d'une ponctuation comme "," "." " ;", etc. En fin de compte, le POS tagger vous dira si un token est un nom, un verbe, un adjectif, etc. Les structures linguistiques étant radicalement différentes d'une langue à l'autre, les bons marqueurs POS doivent s'adapter à chaque langue. Certaines langues sont beaucoup plus difficiles à analyser que d'autres.
Supposons que vous ayez la phrase suivante :
Le marqueur POS renvoie le texte suivant :
- "John": nom propre
- "Does": nom propre
- "is": verbe auxiliaire
- "a": déterminant
- "Go": nom propre
- "developer": nom
- "at": adposition
- "Google": nom propre
- ".": ponctuation
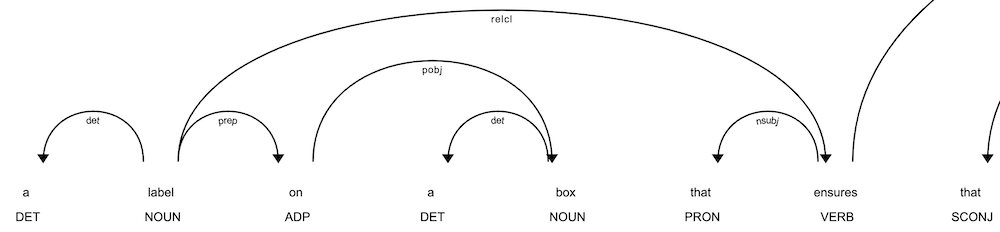
Qu'est-ce que l'analyse de dépendance ?
L'analyse des dépendances dans le traitement du langage naturel (NLP) est une technique d'analyse de la structure grammaticale d'une phrase. Elle permet de comprendre comment les mots d'une phrase sont liés les uns aux autres. Pour ce faire, elle identifie les dépendances entre les mots, c'est-à-dire la façon dont les mots dépendent les uns des autres pour conférer un sens.
L'idée de base de l'analyse syntaxique des dépendances est de construire un arbre de dépendance (ou graphe) dans lequel les nœuds représentent les mots d'une phrase et les arêtes représentent les relations entre ces mots. Chaque arête de l'arbre de dépendance est étiquetée avec le type de relation grammaticale qui existe entre les mots connectés, comme le sujet, l'objet, le modificateur, etc. La racine de l'arbre est généralement le verbe principal ou la clause principale à laquelle les autres mots sont liés.