Introduction au LLaMA 3
Meta a présenté les premières versions de son modèle d'IA open-source Llama 3, qui peut être utilisé pour la création de textes, la programmation ou les chatbots. En outre, Meta a annoncé son intention d'intégrer LLaMA 3 dans ses principales applications de médias sociaux. Cette initiative vise à concurrencer d'autres assistants d'IA, tels que ChatGPT d'OpenAI, Copilot de Microsoft et Gemini de Google.
Comme Llama 2, Llama 3 est un modèle de langue de grande taille librement accessible, avec des poids ouverts, proposé par une entreprise d'IA de premier plan (bien qu'il ne soit pas considéré comme "open source" au sens conventionnel du terme).
Actuellement, Llama 3 peut être téléchargé gratuitement à partir du site web de Meta dans deux tailles de paramètres différentes : 8 milliards (8B) et 70 milliards (70B). Les utilisateurs peuvent s'inscrire pour accéder à ces versions. Llama 3 est proposé en deux variantes : pre-trained, qui est un modèle de base pour la prédiction du prochain jeton, et instruction-tuned, qui est affiné pour adhérer aux commandes de l'utilisateur. Les deux versions ont une limite de contexte de 8 192 tokens.
Dans un entretien avec Dwarkesh Patel, Mark Zuckerberg, le PDG de Meta, a mentionné qu'ils ont formé deux modèles personnalisés en utilisant un cluster de 24 000 GPU. Le modèle 70B a été entraîné avec environ 15 000 milliards de tokens de données et n'a jamais atteint un point de saturation ou une limite à ses capacités. Par la suite, Meta a décidé de se concentrer sur la formation d'autres modèles. L'entreprise a également révélé qu'elle travaillait actuellement sur une version de Llama 3 avec 400 milliards de paramètres, qui, selon des experts tels que Jim Fan de Nvidia, pourrait obtenir des résultats similaires à ceux de GPT-4 Turbo, Claude 3 Opus et Gemini Ultra sur des benchmarks tels que MMLU, GPQA, HumanEval et MATH.
Selon Meta, Llama 3 a été évalué à l'aide de divers critères, notamment MMLU (connaissances de premier cycle), GSM-8K (mathématiques de niveau primaire), HumanEval (codage), GPQA (questions de niveau supérieur) et MATH (problèmes de mots mathématiques). Ces benchmarks démontrent que le modèle 8B surpasse les modèles à poids ouverts tels que Gemma 7B et Mistral 7B Instruct de Google, et que le modèle 70B est compétitif par rapport à Gemini Pro 1.5 et Claude 3 Sonnet.
Meta rapporte que le modèle Llama 3 a été amélioré avec la capacité de comprendre le codage, comme pour Llama 2, et pour la première fois, il a été entraîné en utilisant à la fois des images et du texte. Pour la première fois, il a été entraîné à l'aide d'images et de textes. Toutefois, ses résultats actuels se limitent au texte.
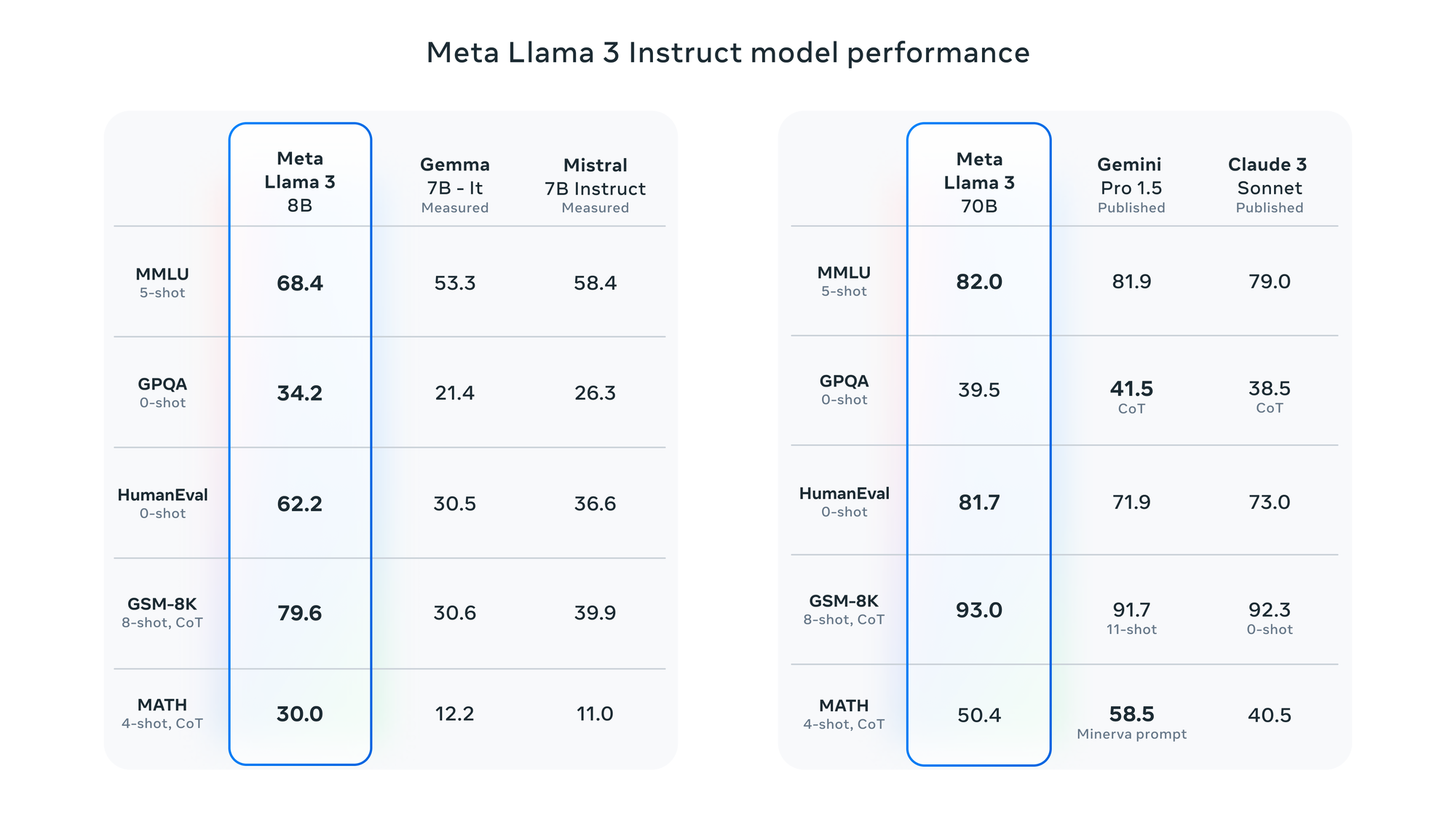 LLaMA 3 Repères
LLaMA 3 Repères