John Doe est développeur web chez Google.
Qu'est-ce que le NER ?
NER signifie Named Entity Recognition (reconnaissance des entités nommées). Il s'agit d'une tâche secondaire qui consiste à identifier et à classer les entités nommées dans un texte dans des catégories prédéfinies telles que les noms de personnes, d'organisations, de lieux, les expressions temporelles, les quantités, les valeurs monétaires, les pourcentages, etc.
Les modèles génératifs tels que ChatGPT, GPT-3.5, GPT-4, LLaMA 3, Yi 34B, ou Mixtral 8x7B, sont très performants en matière d'extraction d'entités.
Le NER est crucial pour de nombreuses applications NLP telles que la réponse aux questions, le résumé de texte et la traduction automatique, car il fournit des informations détaillées sur les éléments clés d'un texte, permettant une compréhension et un traitement plus approfondis. Par exemple, le fait de savoir que "Paris" fait référence à un lieu dans un texte donné peut influencer de manière significative l'interprétation de ce texte et la réponse générée par un système de TAL.
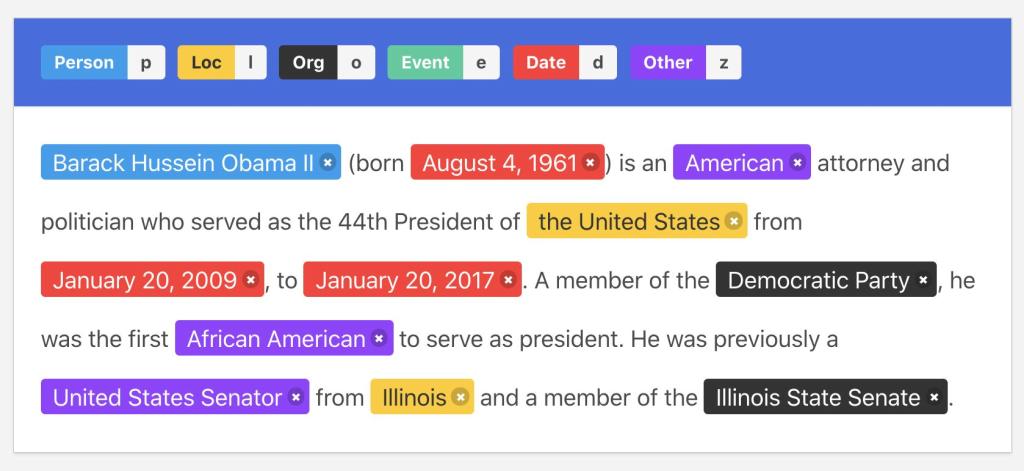
Supposons que vous ayez la phrase suivante :
Vous aimeriez détecter automatiquement que "John Doe" est un nom, que "développeur web" est un titre de poste et que "Google" est une entreprise. C'est exactement ce que NER va faire.