Créez un compte
L'inscription est très rapide. Allez sur la page d'inscription et renseignez email + mot de passe.
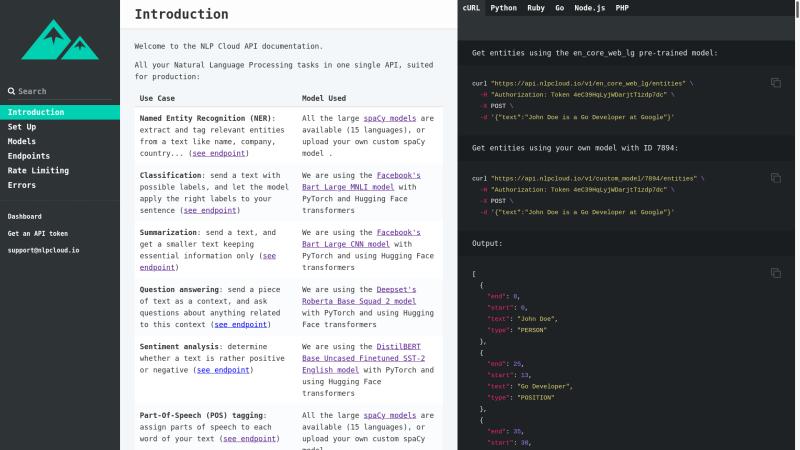
Vous êtes maintenant sur votre dashboard et vous pouvez voir votre token API. Gardez ce token en toute sécurité, vous en aurez besoin pour tous les appels API que vous ferez.
Plusieurs extraits de code sont fournis dans votre tableau de bord afin que vous puissiez rapidement passer à la vitesse supérieure. Pour plus de détails, vous pouvez ensuite lire la documentation.