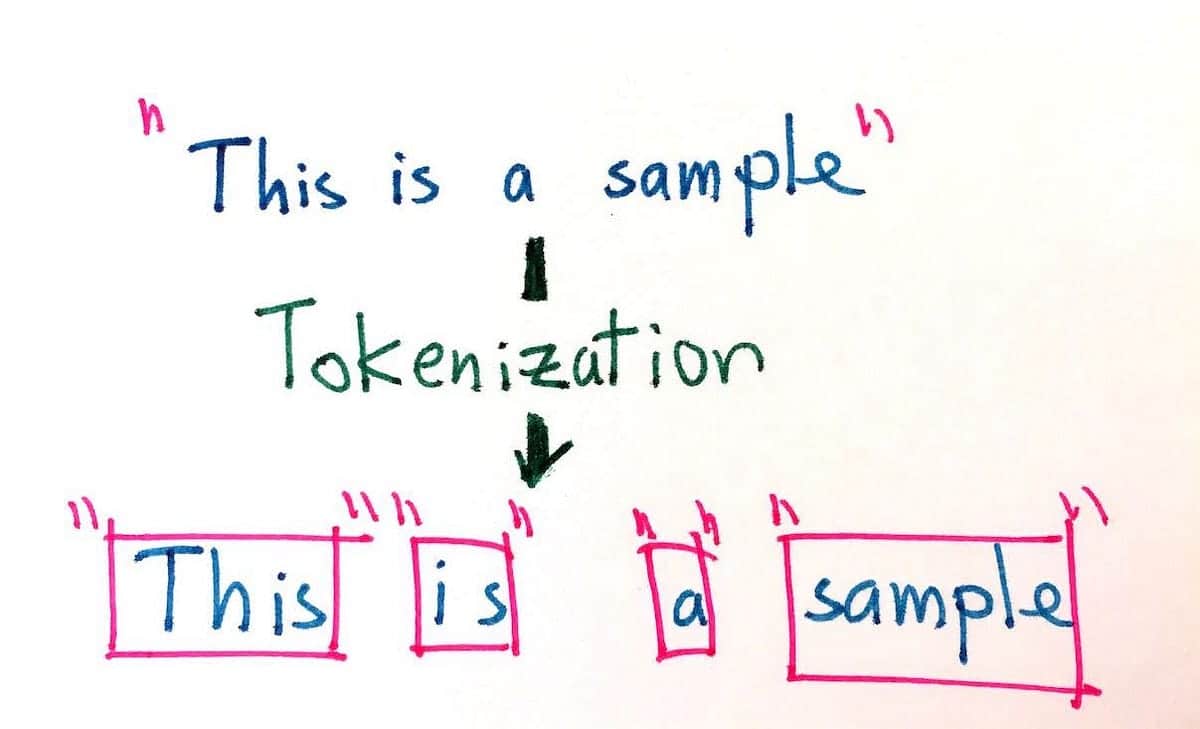
Qu'est-ce que la tokenisation ?
La tokenisation consiste à diviser un texte en entités plus petites appelées tokens. Les tokens sont différents selon le type de tokenizer que vous utilisez. Un token peut être un mot, un caractère ou un sous-mot (par exemple, dans le mot anglais "higher", il y a 2 sous-mots : "high" et "er"). Les signes de ponctuation tels que " !", "." et " ;" peuvent également être des jetons.
La tokenisation est une étape fondamentale de toute opération de traitement du langage naturel. Compte tenu des différentes structures linguistiques existantes, la tokenisation est différente dans chaque langue.
Qu'est-ce que la lémmatisation ?
La lemmatisation consiste à extraire la forme de base d'un mot (typiquement le genre de travail que l'on trouve dans un dictionnaire). Par exemple, le lemme de "apple" serait toujours "apple" mais le lemme de "is" serait "be".
La lemmatisation, comme la tokenisation, est une étape fondamentale dans chaque opération de traitement du langage naturel. Compte tenu des différentes structures linguistiques existantes, la lemmatisation est différente dans chaque langue.