Multi-GPU avec Deepspeed
Si vous ne pouvez pas faire tenir votre modèle dans un seul GPU, vous pouvez essayer de le diviser en plusieurs GPU.
Il s'agit d'une option intéressante pour deux raisons. Premièrement, la mise à l'échelle horizontale d'une infrastructure est souvent moins chère que la mise à l'échelle verticale. C'est vrai pour les serveurs et c'est vrai aussi pour les GPU. Deuxièmement, il est plus facile de mettre la main sur plusieurs petits GPU comme le NVIDIA Tesla T4 que sur de plus gros GPU comme le NVIDIA A40.
Malheureusement, la répartition d'un modèle d'apprentissage automatique entre plusieurs GPU est un défi technique. Hugging Face a fait un excellent article sur le parallélisme des modèles et les choix que vous avez. Lisez-le ici. Mais heureusement, EleutherAI a conçu GPT-NeoX 20B de manière à ce qu'il soit facilement parallélisé sur plusieurs GPU, que ce soit pour l'entraînement ou l'inférence.
L'architecture GPT-NeoX est basée sur Deepspeed. Deepspeed est un framework de Microsoft qui a été conçu à l'origine pour paralléliser les entraînements entre plusieurs GPU, et il est de plus en plus utilisé pour l'inférence également. EleutherAI a fait tout le travail difficile, de sorte que la parallélisation de GPT-NeoX est aussi simple que de changer un nombre dans un fichier de configuration.
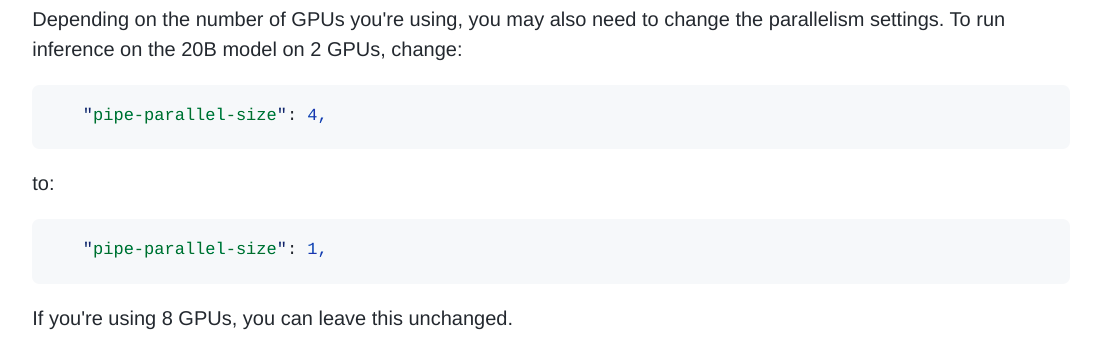
Extract from the GPT-NeoX docs about parallelism
Cependant, le déploiement de Deepspeed en production pour l'inférence en ligne via une API est difficile... Deepspeed n'a pas été conçu pour être facilement intégré dans des serveurs web. Chez NLP Cloud, nous l'avons appris à nos dépens, mais après un travail acharné, nous avons finalement réussi à trouver un moyen efficace de faire fonctionner Deepspeed et GPT-NeoX derrière notre API.
