Batch inference is very powerful because it will take almost the same time for your model to address several requests as it takes to address 1 request. Under the hood some operations will be factorized, so that instead of doing everything n times, the model only has to do it once.
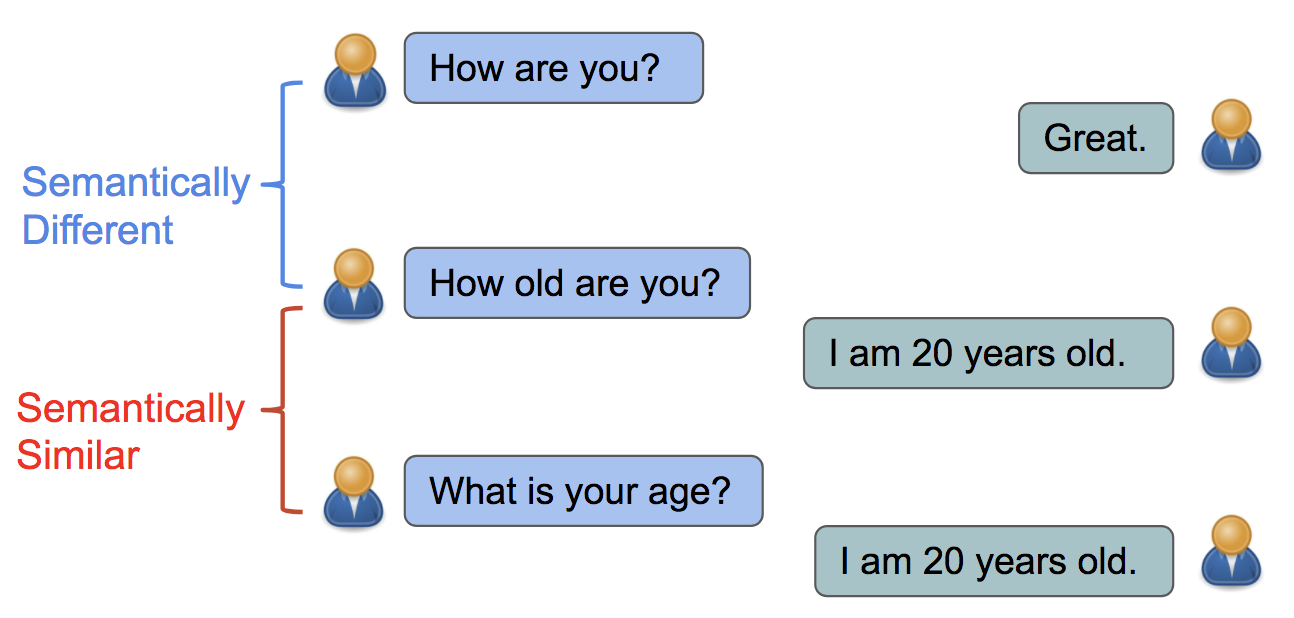
Qu'est-ce que la similarité sémantique ?
La similarité sémantique consiste à déterminer si deux morceaux de texte ont la même signification ou non.
Par exemple, vous voudrez peut-être savoir si les deux blocs de texte suivants parlent de la même chose :
Batch inference is a good way for your model to address more requests faster. Some operations are actually factorized in order to do things only once.
Il est clair qu'ils parlent de la même chose et qu'ils ont à peu près la même signification.
L'envoi de ces deux blocs de texte à un modèle de similarité sémantique donnerait un score de 0,90, ce qui signifie que, selon le modèle, les deux entrées ont la même signification. En revanche, un score faible indiquerait que les entrées n'ont pas la même signification.