Article par Rafał Rybnik, Head of Software Development chez Instytut Badań Pollster

Sauf indication contraire, toutes les images de l'article sont faites par
l'auteur.
Article par Rafał Rybnik, Head of Software Development chez Instytut Badań Pollster
Sauf indication contraire, toutes les images de l'article sont faites par
l'auteur.
Dans la réalité publicitaire en ligne d'aujourd'hui, les tactiques de marketing efficaces dépendent d'une variété de techniques de suivi des utilisateurs, telles que les cookies tiers (et les stockages alternatifs) et les empreintes digitales des appareils. Mais dans un monde de fuites de données, la RGPD, la CCPA, et une législation accrue de protection des données inspirée par celles-ci, cette approche devient obsolète. Safari et Firefox ont déjà des solutions intégrées pour réduire le suivi cross-site. Chrome fonctionne également avec des alternatives. Ainsi, la fin des cookies tiers est pour bientôt. L'identificateur d'Apples pour les annonceurs (IDFA) ne sera bientôt accessible que pour les applications avec le consentement explicite de l'utilisateur. La disparition de la possibilité d'un suivi interdomaines permet aux annonceurs de revenir à la publicité contextuelle.
Dans cet article, je vous montre comment mettre en œuvre le ciblage contextuel basé sur l'API de classification de texte fournie par NLP Cloud. L'approche décrite ici peut être facilement adaptée à toutes les technologies publicitaires (comme les serveurs publicitaires, OpenRTB, etc.).
Parce que les annonceurs ne sont plus en mesure de cibler les utilisateurs individuels en utilisant des cookies tiers, les campagnes publicitaires contextuelles sont hausse à nouveau. Ce pourrait être la seule façon de cibler les intérêts des utilisateurs à une assez grande échelle.

(pic. from Qu'est-ce que la publicité contextuelle
?)
Cela est censé être plus intéressant pour les utilisateurs, car ils vont voir des annonces qui correspondent au sujet des pages du site Web qu'ils visitent.
La plupart des technologies de service publicitaire et des réseaux publicitaires supportent le passage de mots-clés ou de tags. Le texte est le cœur du web et peut être une source d'information extrêmement riche. Cependant, extraire le contexte, les tags et les mots-clés de celui-ci, par exemple à des fins publicitaires ou de recommandation, peut être difficile et long. Même si vous êtes le propriétaire d'un site d'information de taille moyenne, au-delà de quelques tags attribués par l'équipe éditoriale, il sera difficile d'extraire tous les sujets pertinents.
Les premières tentatives d'automatisation de ce processus ont donné lieu à des erreurs plus ou moins hilarantes dans le passé :
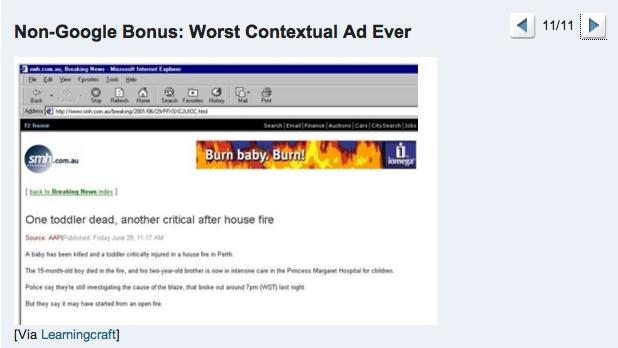
(pic. from Mauvais placement
publicitaire)
Heureusement, les progrès en traitement du langage naturel permettent des correspondances beaucoup plus précises, en moins de temps. La classification textuelle est l'attribution de catégories ou d'étiquettes compatibles avec le contenu textuel.
Considérons une page d'exemple avec des articles sur une variété de sujets :

Notre objectif est d'obtenir des placements publicitaires liés au contenu de l'article.
Les conditions que notre solution doit remplir :
Notez que les systèmes publicitaires et le développement du web sont hors du champ d'application de cet article, mais les concepts généraux restent les mêmes quels que soient les outils et les technologies utilisés.
Ma solution préférée dans de tels cas est de séparer la logique qui gère la classification de texte dans une API séparée. Nous avons deux options : la créer nous-mêmes ou utiliser une solution prête à l'emploi.
La préparation d'un simple moteur de classification de texte à l'aide de bibliothèques Python et du Natural Language Processing est une tâche pour un après-midi. Mais le problème se pose en termes de précision et de service de trafic accru.
Si vous êtes propriétaire d'un site Web, il est peu probable que vous vouliez jouer avec les modèles d'apprentissage automatique et d'évaluation. Ainsi, nous déléguerons autant que nous le pouvons à une solution externe. Notez que nous n'avons pas l'intention d'envoyer ici des données utilisateur mais seules les données appartenant au site Web. Cela rend l'utilisation d'outils contextuels externes de ciblage beaucoup plus simple du point de vue de la confidentialité des utilisateurs.
NLP Cloud est un fournisseur d'APIs multiples pour le traitement de texte à l'aide de modèles d'apprentissage automatique. L'un d'entre eux est le classificateur de texte, qui semble prometteur en termes de mise en œuvre simple.

Avec l'API NLP Cloud, vous pouvez essayer quel algorithme pourrait être utile à votre business case.
Comme le moteur du site est basé sur Python (Flask), nous commençons par écrire un simple client pour l'API NLP :
import pandas as pd
import requests
import json
class TextClassification:
def __init__(self, key, base='https://api.nlpcloud.io/v1/bart-large-mnli',):
self.base = base
self.headers = {
"accept": "application/json",
"content-type": "application/json",
"Authorization": f"Token {key}"
}
def get_keywords(self, text, labels):
url = f"{self.base}/classification"
payload = {
"text":text,
"labels":labels,
"multi_class": True
}
response = requests.request("POST", url, json=payload, headers=self.headers)
result = []
try:
result = dict(zip(response.json()['labels'], response.json()['scores']))
except:
pass
return result
tc = TextClassification(key='APIKEY')
print(
tc.get_keywords(
"Football is a family of team sports that involve, to varying degrees, kicking a ball to score a goal. Unqualified, the word football normally means the form of football that is the most popular where the word is used. Sports commonly called football include association football (known as soccer in some countries); gridiron football (specifically American football or Canadian football); Australian rules football; rugby football (either rugby union or rugby league); and Gaelic football.[1][2] These various forms of football share to varying extent common origins and are known as football codes.",
["football", "sport", "cooking", "machine learning"]
)
)Résultats:
{
'labels': [
'sport',
'football',
'machine learning',
'cooking'
],
'scores': [
0.9651273488998413,
0.938549280166626,
0.013061746023595333,
0.0016104158712550998
]
}Très bien. Chaque étiquette se voit attribuer sa pertinence au sujet sans effort.
L'idée est que la sélection des bannières à afficher sera faite par un système de service publicitaire (la décision sera basée sur les scores des étiquettes assignées individuellement). Par conséquent, afin de ne pas exposer les clés de l'API et d'avoir plus de contrôle sur les données, nous allons écrire un proxy simple :
@app.route('/get-labels',methods = ['POST'])
def get_labels():
if request.method == 'POST':
try:
return tc.get_keywords(request.json['text'], request.json['labels'])
except:
return []Supposons que nous avons 3 campagnes publicitaires à lancer :

Société d'assurance (mot clé : insurance)

Société d'énergie (mot clé : renewables)

Coiffeur (mot clé : good look)
Let’s sketch a mechanism on the front-end, which will manage the display of an appropriate creative.
function displayAd(keyword, placement_id) {
var conditions = {
false: ' ',
"insurance": '
',
"insurance": ' ',
"renewables": '
',
"renewables": ' ',
"good look": '
',
"good look": ' '
}
var banner = document.querySelector(placement_id);
banner.innerHTML = conditions[keyword];
}
'
}
var banner = document.querySelector(placement_id);
banner.innerHTML = conditions[keyword];
}Voici notre serveur de pub 🤪
Maintenant en utilisant fetch, nous allons récupérer des étiquettes pour le texte d'un article, que nous obtenons en utilisant son sélecteur :
var text = document.querySelector("#article").textContent;
var labels = ["insurance", "renewables", "good look"];
var myHeaders = new Headers();
myHeaders.append("Content-Type", "application/json");
var raw = JSON.stringify({"text":text,"labels":labels});
var requestOptions = {
method: 'POST',
headers: myHeaders,
body: raw,
};
fetch("http://127.0.0.1:5000/get-labels", requestOptions)
.then(response =>
response.json()
)
.then(result => {
if (result == []){
console.log("self-promote");
displayAd(false, "#banner");
} else {
var scores = result['scores'];
var labels = result['labels'];
if (Math.max(...scores) >= 0.8) {
console.log("Ad success");
var indexOfMaxScore = scores.reduce((iMax, x, i, arr) => x > arr[iMax] ? i : iMax, 0);
displayAd(labels[indexOfMaxScore], "#banner");
} else {
displayAd(false, "#banner");
}
}
})
.catch(error => console.log('error', error));Notez que nous n'afficherons l'annonce client que si la note est supérieure à 0,8 :
Math.max(…scores) >= 0.8
Sinon, on affiche de l'autopromotion.
Il s'agit bien sûr d'une valeur arbitraire, qui peut être resserrée et desserrée au besoin.
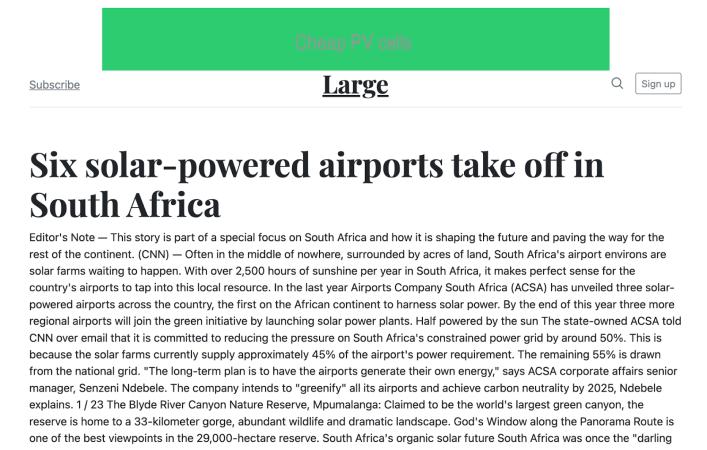
Les nouvelles sur les sources d'énergie renouvelables correspondent aux annonces
de cellules photovoltaïques.

Les infos sur les dangers dans la maison peuvent augmenter l'intention d'acheter
une assurance.
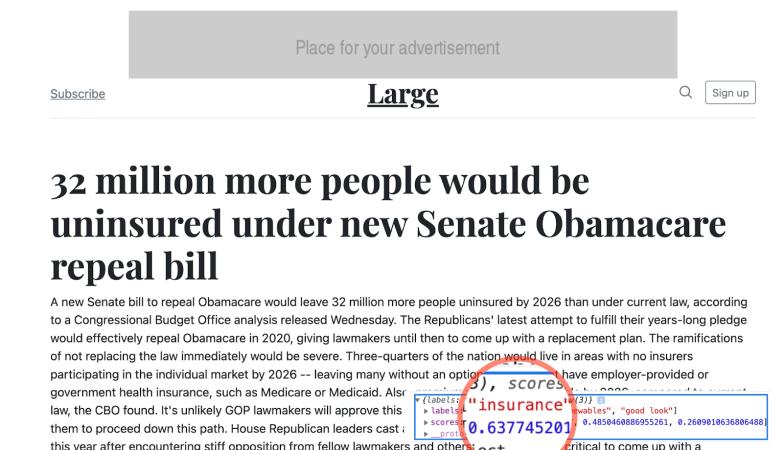
Bien qu'une annonce sur l'assurance eut été appropriée pour l'article, elle n'a
pas été affichée parce que le bon niveau de pertinence n'a pas été atteint.
Le lecteur attentionné remarquera que l'exemple de la bannière de coiffeur n'est pas apparu. C'est parce que l'objet des articles est axé sur les infos sérieuses du monde, où les problèmes de mode ne sont pas abordés. Pour être en mesure de mettre en œuvre la campagne, vous devez choisir un site différent ou repenser votre stratégie de mots clés.
Le grand avantage d'utiliser un fetch asynchrone est le chargement plus rapide de
la page. Cependant, en même temps, l'annonce ne s'affichera qu'après le téléchargement des étiquettes.
Pour cette raison et pour réduire les coûts, il est préférable d'implémenter une certaine forme de cache
dans un environnement de production.
Une modification supplémentaire pourrait être simplement de stocker les étiquettes directement dans la base de données. Pour les articles peu fréquemment mis à jour, cela a certainement du sens.
Cependant, une solution basée sur une API séparée, que nous pouvons alimenter par n'importe quel texte et obtenir ses étiquettes, nous donne la possibilité d'utiliser le code JS pratiquement sur n'importe quelle page en temps quasi réel, même sans accès au moteur !
Le plus grand défi en utilisant le ciblage contextuel est de l'utiliser sur les sites de nouvelles. Beaucoup de sujets apparaissent dans les articles publiés sur ces sites, y compris ceux qui sont en phase avec l'industrie de l'annonceur. Mais en même temps, les tons sensationnels, souvent tristes, des histoires qu'ils contiennent ne sont pas un bon endroit pour faire de la publicité.
L'API de Classification de texte de NLP Cloud, d'autre part, fait un bon travail de marquage des textes, donc nous pourrions aussi bien répéter tout le processus, cette fois en gardant à l'esprit d'exclure des textes sur un sujet donné.
Merci de lire. J'espère que vous avez aimé lire autant que j'ai aimé écrire ceci pour vous.