Comment affiner LLaMA, OpenLLaMA et XGen, avec JAX sur un GPU ou une TPU ?
LLaMA, OpenLLaMA et XGen sont des modèles d'IA générative de pointe. Ces modèles donnent des résultats encore meilleurs lorsqu'ils sont affinés sur vos propres données. Dans cet article, nous allons voir comment affiner ces modèles à la fois sur un GPU et un TPU, en utilisant JAX et la bibliothèque EasyLM.
LLaMA, OpenLLaM et XGen
Le modèle LLaMA a été publié par Meta en février 2023. Ce modèle d'IA génératif est un modèle open-source proposé en plusieurs tailles : 7B paramètres, 13B paramètres, 33B paramètres et 65B paramètres.
En juin 2021, lorsque GPT-J a été publié, le monde a commencé à réaliser que les modèles d'IA générative open-source pouvaient sérieusement concurrencer OpenAI GPT-3. Aujourd'hui, avec LLaMA, la barre a clairement été relevée et ce modèle semble être une très bonne alternative open-source à OpenAI ChatGPT et GPT-4.
La licence de LLaMA n'est cependant pas favorable aux entreprises : ce modèle ne peut pas être utilisé à des fins commerciales... Mais la bonne nouvelle, c'est qu'il existe maintenant d'autres modèles.
OpenLLaMA, publié en juin 2023, est une version alternative de LLaMA, développée par l'équipe Berkeley AI Research, qui donne de très bons résultats et peut être utilisée pour les entreprises. 2 versions sont disponibles à ce jour : 7B paramètres et 13B paramètres.
XGen, publié par Salesforce en juin 2023, est un autre modèle fondamental très puissant qui peut être utilisé dans des applications commerciales. Seule une version avec des paramètres 7B est disponible à ce jour. Il convient de noter que ce modèle prend en charge un contexte de 8k tokens, alors que LLaMA et OpenLLaMA ne prennent en charge qu'un contenu de 2k tokens.
Pourquoi affiner votre propre modèle ?
Les modèles ci-dessus sont des modèles fondateurs, ce qui signifie qu'ils ont été entraînés de manière non supervisée sur un large corpus de textes.
Ces modèles d'IA fondamentaux constituent généralement une bonne base, mais ils doivent être adaptés pour comprendre correctement ce que vous voulez et produire de bons résultats. Le moyen le plus simple d'y parvenir est d'utiliser l'apprentissage à quelques reprises (également connu sous le nom d'"ingénierie des requêtes"). N'hésitez pas à lire notre guide d'apprentissage dédié à la photographie à quelques balles ici.
L'apprentissage en quelques étapes est pratique car il peut être effectué à la volée sans avoir à créer une nouvelle version du modèle d'IA génératif, mais il n'est parfois pas suffisant.
Afin d'obtenir des résultats de pointe, vous voudrez affiner un modèle d'IA pour votre propre cas d'utilisation. Cela signifie que vous modifierez certains paramètres du modèle sur la base de vos propres données, puis que vous obtiendrez votre propre version du modèle.
Le réglage fin est beaucoup moins coûteux que l'apprentissage d'un modèle d'IA génératif à partir de zéro, mais il nécessite toujours de la puissance de calcul, de sorte que vous avez besoin d'un matériel avancé pour régler votre propre modèle. Certaines techniques alternatives récentes de réglage fin nécessitent moins de puissance de calcul (voir p-tuning, prompt tuning, soft tuning, parameter efficient fine-tuning, adapters, LoRA, QLoRA...) mais jusqu'à présent nous n'avons pas réussi à obtenir le même niveau de qualité avec ces techniques et nous n'allons donc pas les mentionner dans ce tutoriel.
Mise au point de LLaMA sur une TPU avec JAX et EasyLM
Dans ce tutoriel, nous nous concentrons sur le réglage fin de LLaMA avec la bibliothèque EasyLM, publiée par l'équipe Berkeley AI Research : https://github.com/young-geng/EasyLM. This library is based on JAX which makes the fine-tuning process fast and compatible with both GPUs and Google TPUs.
Vous pouvez également affiner OpenLLaMA ou XGen en utilisant la même technique.
Nous réglons ici LLaMA 7B sur une Google TPU V3-8, mais vous pouvez parfaitement faire la même chose sur un GPU A100 (il suffit de lire attentivement la partie "Installation" dans la documentation EasyLM qui est légèrement différente). Bien sûr, vous pouvez aussi affiner des versions plus grandes de LLaMA (13B, 33B, 65B...) mais vous aurez besoin de beaucoup plus qu'une TPU V3-8 ou un simple GPU A100.
Nous y voilà !
Tout d'abord, créez un ensemble de données de génération de texte pour votre cas d'utilisation, au format JSONL, en utilisant "text" comme clé pour chaque exemple. Voici un jeu de données simple d'analyse de sentiments :
{"text":"[Content]: I love NLP Cloud, this company is awesome!\n[Sentiment]: Positive"}
{"text":"[Content]: Training LLMs is a complex but rewarding process.\n[Sentiment]: Neutral"}
{"text":"[Content]: My fine-tuning keeps crashing because of an OOM error! It just does not work at all!\n[Sentiment]: Negative"}
Veuillez noter quelques points importants. Tout d'abord, cet ensemble de données ne contient que 3 exemples pour des raisons de simplicité, mais dans la réalité, vous aurez besoin de beaucoup plus d'exemples. 300 exemples sont généralement un bon début. Deuxièmement, lorsque vous utiliserez votre modèle affiné pour l'inférence, vous devrez suivre strictement le même formatage, en utilisant les préfixes "[Content] :" et "[Sentiment] :". Enfin, la mention "</s> ;" est importante car elle signifie que le modèle doit cesser de générer des données à cet endroit. Vous trouverez d'autres exemples de jeux de données dans la documentation de NLP Cloud : Pour en savoir plus, cliquez ici.
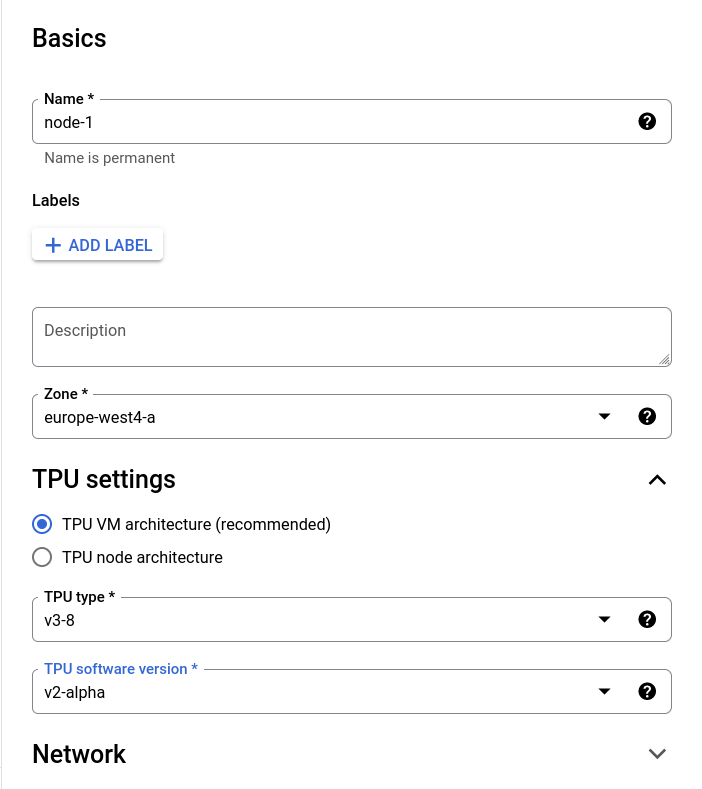
Créez une VM TPU V3-8 sur Google Cloud avec la version logicielle V2 Alpha :
Connectez-vous en SSH à la VM et installez EasyLM :
git clone https://github.com/young-geng/EasyLM
cd EasyLM
bash ./scripts/tpu_vm_setup.sh
Si vous entraînez votre modèle pour un contexte de 1024 tokens, vous devrez diviser le nombre de tokens renvoyés par 1024.
Si vous entraînez votre modèle pour un contexte de 2048 jetons, vous devrez diviser le nombre de jetons retournés par 2048.
Ce nombre sera le nombre de pas par époque. Par exemple, si vous voulez vous entraîner pendant 5 époques (ce qui est généralement un bon réglage), vous devrez multiplier ce nombre par 5 et mettre la valeur résultante dans --total_steps ci-dessous.
Voici un exemple concret : si votre jeu de données contient 100 000 tokens, et que vous souhaitez un contexte de 1024 tokens et 5 époques, votre nombre total d'étapes sera de (100 000/1024)*5 = 488.
En fonction de la longueur de votre contexte, définissez --train_dataset.json_dataset.seq_length comme 1024 ou 2048 ci-dessous. Notez que le réglage fin d'un modèle pour un contexte de 2048 tokens nécessite plus de mémoire, donc si ce n'est pas strictement nécessaire, nous vous recommandons de vous en tenir à un contexte de 1024 tokens.
Vous pouvez maintenant lancer le processus de réglage fin :
nohup python -u EasyLM/EasyLM/models/llama/llama_train.py \
--total_steps=your number of steps \
--save_model_freq=usually same as your number of steps \
--optimizer.adamw_optimizer.lr_warmup_steps=usually 10% of total steps \
--train_dataset.json_dataset.path='/path/to/your/dataset' \
--train_dataset.json_dataset.seq_length=1024 or 2048 \
--load_checkpoint='params::/path/to/converted/model' \
--tokenizer.vocab_file='/path/to/tokenizer' \
--logger.output_dir=/path/to/output \
--mesh_dim='1,4,2' \
--load_llama_config='7b' \
--train_dataset.type='json' \
--train_dataset.text_processor.fields='text' \
--optimizer.type='adamw' \
--optimizer.accumulate_gradient_steps=1 \
--optimizer.adamw_optimizer.lr=0.002 \
--optimizer.adamw_optimizer.end_lr=0.002 \
--optimizer.adamw_optimizer.lr_decay_steps=100000000 \
--optimizer.adamw_optimizer.weight_decay=0.001 \
--optimizer.adamw_optimizer.multiply_by_parameter_scale=True \
--optimizer.adamw_optimizer.bf16_momentum=True &
Quelques explications :
--save_model_freq : fréquence à laquelle vous souhaitez sauvegarder votre modèle au cours du processus. Si vous n'effectuez qu'un réglage fin sur un petit ensemble de données, vous pouvez sauvegarder à la fin du processus uniquement, et dans ce cas, cette valeur sera égale à --total_steps.
--optimizer.adamw_optimizer.lr_warmup_steps : 10% du nombre total de pas est généralement une bonne valeur.
--tokenizer.vocab_file : le chemin vers le fichier tokenizer.model. Par exemple, si vous utilisez le dépôt decapoda sur HuggingFace, voici le lien vers le tokenizer : https://huggingface.co/decapoda-research/llama-7b-hf/resolve/main/tokenizer.model
--logger.output_dir : chemin vers le modèle final et les logs
Les autres paramètres peuvent être laissés tels quels.
Une fois le processus d'ajustement terminé, vous pouvez récupérer votre modèle au chemin spécifié dans --logger.output_dir.
Utilisation du modèle affiné pour l'inférence
Vous disposez maintenant de votre propre modèle perfectionné et vous voulez l'utiliser, bien sûr !
Une première stratégie consiste à utiliser la bibliothèque EasyLM pour l'inférence. Dans ce cas, vous pouvez lancer le serveur d'inférence comme suit :
Il suffit ensuite d'envoyer vos requêtes à l'aide de cURL comme suit :
curl "http://0.0.0.0:5007/generate" \
-H "Content-Type: application/json" \
-X POST -d '{"prefix_text":["[Content]: EasyLM works really well!\n[Sentiment]:"]}'
Une deuxième stratégie consiste à exporter votre modèle au format HuggingFace afin d'effectuer une inférence avec un autre cadre. Voici comment vous pouvez l'exporter :
2023 a été une étape importante pour les modèles d'IA générative open-source. À ce jour, tout le monde peut utiliser d'excellents modèles tels que LLaMA, OpenLLaMA, XGen, Orca, Falcon...
L'affinage de ces modèles est le meilleur moyen d'obtenir des résultats de pointe, adaptés à votre propre cas d'utilisation, qui peuvent dépasser de manière significative les meilleurs modèles d'IA propriétaires tels que ChatGPT (GPT-3.5), GPT-4, Claude...
Dans ce guide, je vous ai montré comment affiner LLaMA, OpenLLaMA et XGen. Si vous avez des questions, n'hésitez pas à me contacter, et si vous voulez facilement affiner et déployer des modèles d'IA générative avancés sans aucune complexité technique, have a look at the NLP Cloud dedicated documentation!
Mark
Ingénieur en apprentissage automatique chez NLP Cloud