Introduction to LLaMA 3
Meta has introduced initial versions of their Llama 3 open-source AI model, which can be utilized
for text creation, programming, or chatbots. Furthermore, Meta announced its plans to incorporate LLaMA 3 into its primary social media applications. This
move aims to compete with other AI assistants, such as OpenAI's ChatGPT, Microsoft's Copilot, and
Google's Gemini.
Similar to Llama 2, Llama 3 stands out as a freely accessible large language model with open
weights, offered by a leading AI company (although it doesn't qualify as "open source" in the
conventional sense).
Currently, Llama 3 can be downloaded for free from Meta's website in two different parameter sizes:
8 billion (8B) and 70 billion (70B). Users can sign up to access these versions. Llama 3 is offered in
two variants: pre-trained, which is a basic model for next token prediction, and instruction-tuned,
which is fine-tuned to adhere to user commands. Both versions have a context limit of 8,192 tokens.
In an interview with Dwarkesh Patel, Mark Zuckerberg, the CEO of Meta, mentioned that they trained
two custom-built models using a 24,000-GPU cluster. The 70B model was trained with approximately 15
trillion tokens of data, and it never reached a point of saturation or a limit to its capabilities.
Afterward, Meta decided to focus on training other models. The company also revealed that they are
currently working on a 400B parameter version of Llama 3, which experts like Nvidia's Jim Fan believe
could perform similarly to GPT-4 Turbo, Claude 3 Opus, and Gemini Ultra on benchmarks like MMLU, GPQA,
HumanEval, and MATH.
According to Meta, Llama 3 has been assessed using various benchmarks, including MMLU (undergraduate
level knowledge), GSM-8K (grade-school math), HumanEval (coding), GPQA (graduate-level questions), and
MATH (math word problems). These benchmarks demonstrate that the 8B model outperforms open-weights
models such as Google's Gemma 7B and Mistral 7B Instruct, and the 70B model is competitive against
Gemini Pro 1.5 and Claude 3 Sonnet.
Meta reports that the Llama 3 model has been improved with the ability to comprehend coding, similar
to Llama 2, and for the first time, it has been trained using both images and text. However, its current
output is limited to text.
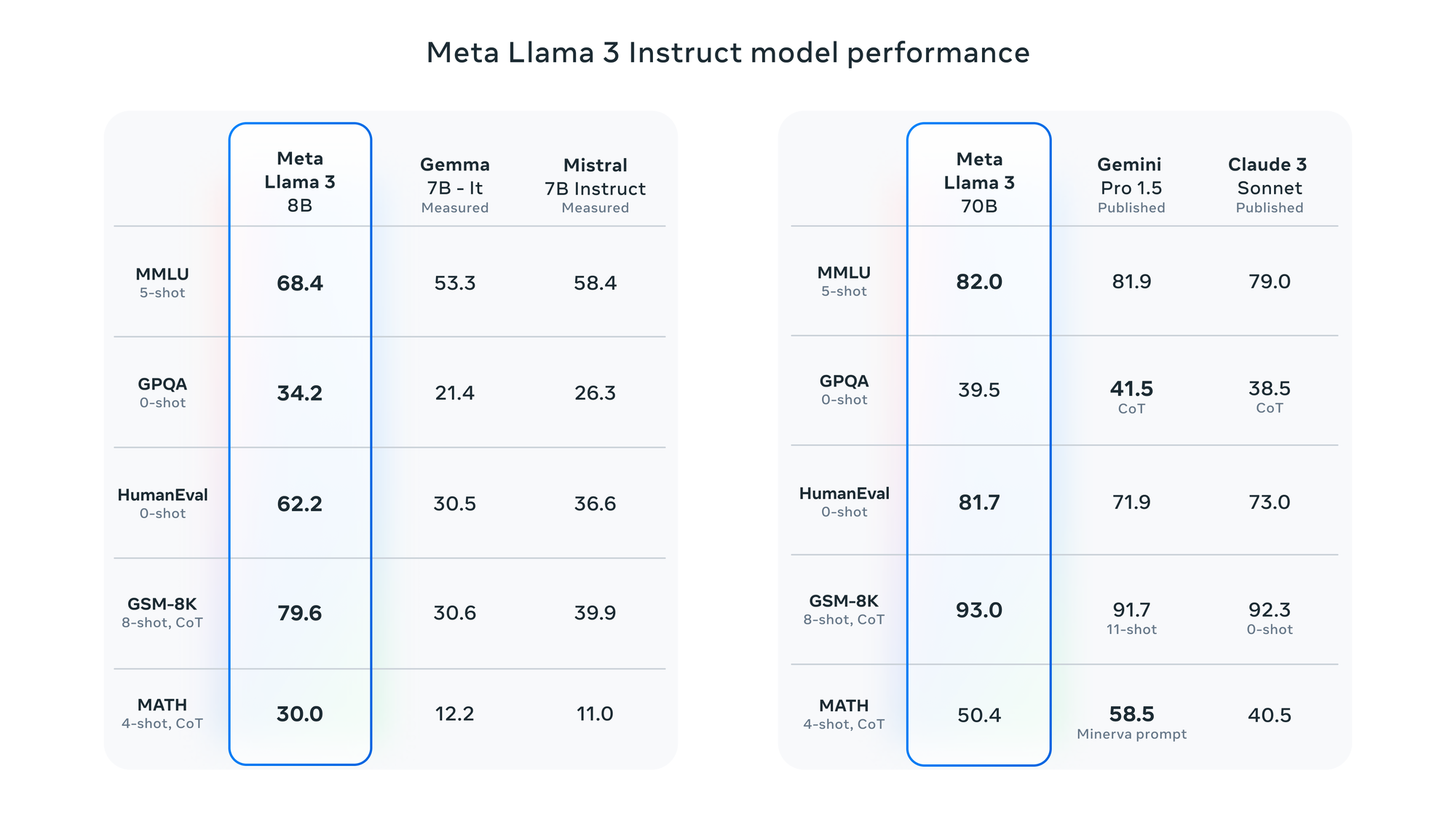 LLaMA 3 Benchmarks
LLaMA 3 Benchmarks