Deploying GPT-NeoX 20B in production is a challenge and we learned it the hard way at NLP Cloud... In this article we're telling you more about several tricks related to using GPT-NeoX 20B, and especially how to deal with DeepSpeed in production.

Deploying GPT-NeoX 20B in production is a challenge and we learned it the hard way at NLP Cloud... In this article we're telling you more about several tricks related to using GPT-NeoX 20B, and especially how to deal with DeepSpeed in production.
GPT-NeoX 20B is the biggest open-source Natural Language Processing model as of this writing.
It was released by EleutherAI 2 weeks ago. It was trained on 20 billion parameters, after a 1 year hard work full of challenges. One of their main difficulties seemed to be the ability to set up a proper parallel architecture so that the model can be efficiently trained on multiple GPUs.
Their previous model, GPT-J, was trained on Google TPUs and was designed to be used on TPUs. GPT-NeoX 20B's inner architecture is radically different and is made to be used on GPUs. The idea is that it should be the first of a series of even bigger models (the goal here is to catch up with GPT-3).
GPT-NeoX 20 is a text generation model, meaning that it can write text for you and actually achieve almost any Natural Language Processing use case with a great accuracy: blog post generation, chatbots, text classification, sentiment analysis, keywords extraction, code generation, entity extraction, intent classification, question answering, and more...
No doubt many researchers and companies will leverage this new model and get great results. But there is a challenge: how to deploy GPT-NeoX 20B?
The first challenge that one faces when trying to deploy GPT-NeoX 20B in production, is the advanced hardware it requires.
It was still possible to deploy GPT-J on consumer hardware, even if it was very expensive. For example, you could deploy it on a very good CPU (even if the result was painfully slow) or on an advanced gaming GPU like the NVIDIA RTX 3090. But GPT-NeoX 20B is so big that it's not possible anymore.
Basically GPT-NeoX requires at least 42GB of VRAM and 40 GB of disk space (and yes we're talking about the slim fp16 version here). Few GPUs match these requirements. The main ones are the NVIDIA A100, A40, and RTX A6000.
Not only are these GPUs very expensive, but it's also hard to get your hand on one of them these days because of the global semiconductor shortage.
The best solution here is to go for a multi-GPU architecture.
If you can't fit your model into one single GPU, you can try to split it into several GPUs.
It's an interesting option for 2 reasons. First, scaling an infrastructure horizontally is often cheaper than scaling vertically. It's true for servers and it's true for GPUs too. Secondly, it's easier to get your hand on several small GPUs like the NVIDIA Tesla T4 than bigger GPUs like the NVIDIA A40.
Unfortunately, splitting a machine learning model into several GPUs is a technical challenge. Hugging Face made a great article about model parallelism and the choices you have. Read it here. But luckily, EleutherAI designed GPT-NeoX 20B so that it is easily parallelized on several GPUs, whether it's for training or inference.
The GPT-NeoX architecture is based on Deepspeed. Deepspeed is a framework from Microsoft that was originally designed to parallelize trainings among several GPUs, and it is more and more used for inference too. EleutherAI did all the hard work, so parallelizing GPT-NeoX is as simple as changing a number in a configuration file.
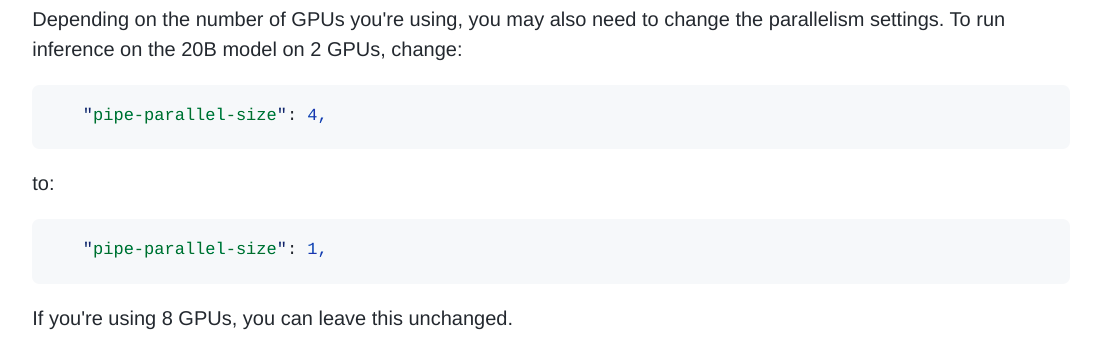
Extract from the GPT-NeoX docs about parallelism
However, deploying Deepspeed in production for online inference through an API is hard... Deepspeed was not designed to be easily integrated into web servers. At NLP Cloud, we learned it the hard way but after some hard work we finally managed to come up with an efficient way to get Deepspeed and GPT-NeoX to work behind our API.
So let's assume you managed to provision the proper hardware and correctly deploy GPT-NeoX 20B with Deepspeed. There are now a couple of caveats you should be aware of.
First, compared to GPT-J, the parameters (top k, top p, and temperature) don't have the same effects on the model. So if you managed to find a good configuration for GPT-J, don't take it for granted: you will have to make new tests with GPT-NeoX.
Last of all, even if the input size can go up to 2048 tokens, it will require more memory than the base 42GB mentioned above...
GPT models are quite slow, and GPT-NeoX 20B is no exception. So in order to improve the throughput of your application, you might want to work on a batch inference solution.
For the moment we haven't come up with a good solution for that at NLP Cloud.
The GPT-NeoX code is made so that one can perform several inferences at the same time within one single request. But in our tests, the response time grew linearly with the number of inferences, which kind of defeats the purpose of batch inference...
GPT-NeoX 20B is definitely hard to deploy in production. The quality of text generation is amazing, but few will have the capacity to actually install this model.
More than ever, it seems that the solution will be to rely on a Cloud service like NLP Cloud in order to use this model. Try GPT-NeoX 20B on NLP Cloud here!
If you have feedbacks on this article please don't hesitate to contact us, it will be great to hear your opinion on this!
Abhinav
Devops engineer at NLP Cloud