Perseverance is just getting started, and already has provided some of the most iconic visuals in space exploration history. It reinforces the remarkable level of engineering and precision that is required to build and fly a vehicle to the Red Planet.
What is Text Classification?
Text classification is the process of categorizing a block of text. As an option, you can ask the AI to choose a category among a list of categories you gave beforehand.
Generative AI models like ChatGPT, GPT-3.5, GPT-4, LLaMA 3, Yi 34B, and Mixtral 8x7B, are very good at performing text classification.
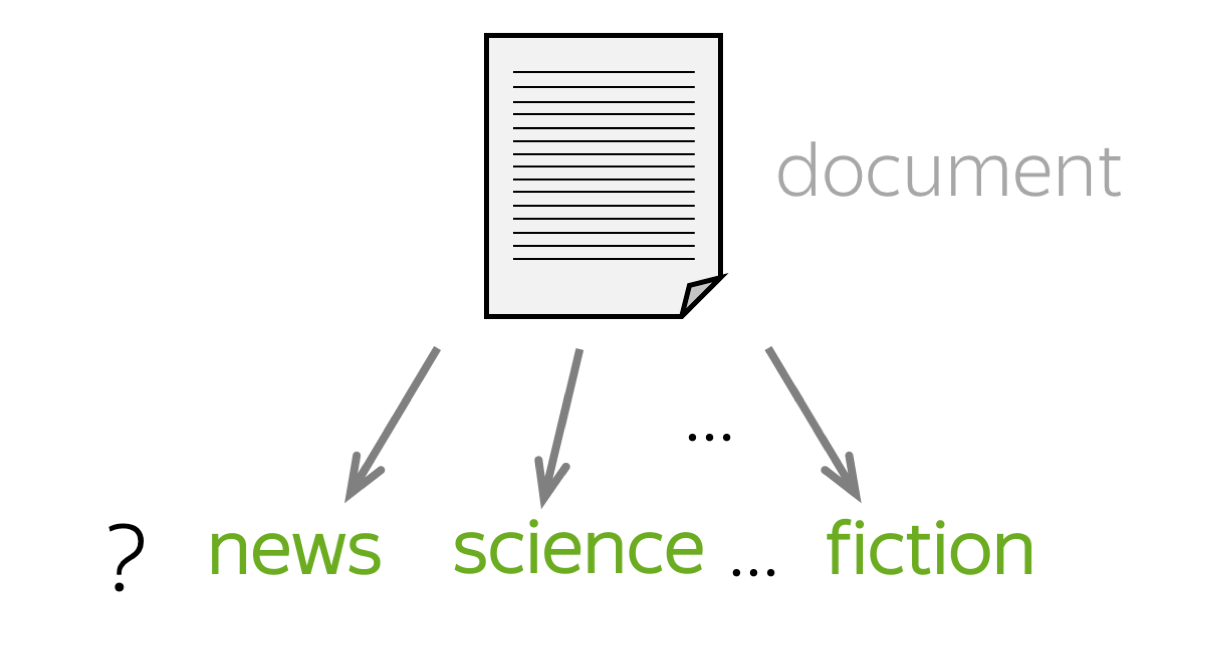
Let's say you have the following block of text:
Let's also say that you also have the following categories: space, science, and food.
Now the question is: which ones of these categories apply best to this block of text? Answer is space and science of course.
If you don't suggest any candidate categories, the AI will suggest the best category possible based on the data it was trained on.