John Doe is a Go developer at Google.
What is Part-Of-Speech (POS) Tagging?
The goal of a Part-of-Speech tagger is to assign parts of speech to every token in your text. A token is a word, most of the time, but it can also be punctuation like "," "." ";" etc. In the end, the POS tagger will tell you whether a token is a noun, a verb, an adjective, etc. As language structures are radically different from one language to another, good POS taggers have to adapt to each language. Some languages are much harder to analyze than others.
Let's say you have the following sentence:
The POS tagger will return the following:
- "John": proper noun
- "Does": proper noun
- "is": auxiliary verb
- "a": determiner
- "Go": proper noun
- "developer": noun
- "at": adposition
- "Google": proper noun
- ".": punctuation
What is Dependency Parsing?
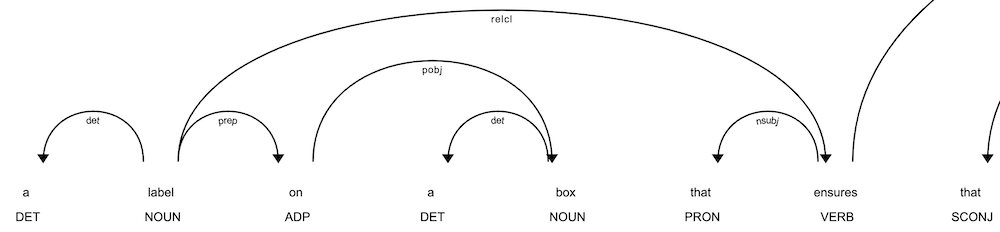
Dependency parsing in Natural Language Processing (NLP) is a technique for analyzing the grammatical structure of a sentence. It helps in understanding how words in a sentence relate to each other. This is achieved by identifying dependencies between words, essentially marking how words depend on each other to confer meaning.
The core idea behind dependency parsing is to construct a dependency tree (or graph) where nodes represent the words in a sentence, and the edges represent the relationships between these words. Each edge in the dependency tree is labeled with the type of grammatical relationship that exists between the connected words, such as subject, object, modifier, etc. The root of the tree is usually the main verb or the main clause that the other words relate to.